みなさん、こんにちは!
前回、Chrome拡張機能の作り方を勉強したよーという記事を書きました。
そこでプラグインのサンプル的なのをアップしましたが、折角なのでもう少し改修して使えそうな拡張機能として残すことにしました。
作ったものはこんな感じのものです。
現在表示されているwebページから、ボタンをポチっと押すと、指定した情報を抽出できるよ、というプラグインです。
前回のプラグインは、Googleの検索結果ページから見出しのみを抽出するという超限定的にして使い道のないものでしたが、
今回はそれを汎用化して、CSSセレクタを入力して抽出ボタンを押下すると、取得した要素のinnerHTMLを取得してくれる、という機能にしました。
これだけじゃまだ微妙なんで、セレクタの保存/取得の機能も付与しておきました。
保存したセレクタは、リスト表示された文字列をポチっと押せばテキスト枠にコピーされますので、すぐに抽出できます。
例えば、前回と同じになってしまいますが、Googleの検索結果ページから見出しを抽出したいのであれば、一番左上のテキストボックスに
[text] #ires .g .r a[/text]
と入力して抽出ボタンを押下すればタイトル一覧が抽出できます。
他にも、Twitterページホームのツイート一覧ページから、ツイートを抽出したいのであれば、
[text] #stream-items-id > li .js-tweet-text-container > p[/text]
と入力すれば、ツイート一覧が抽出できます。
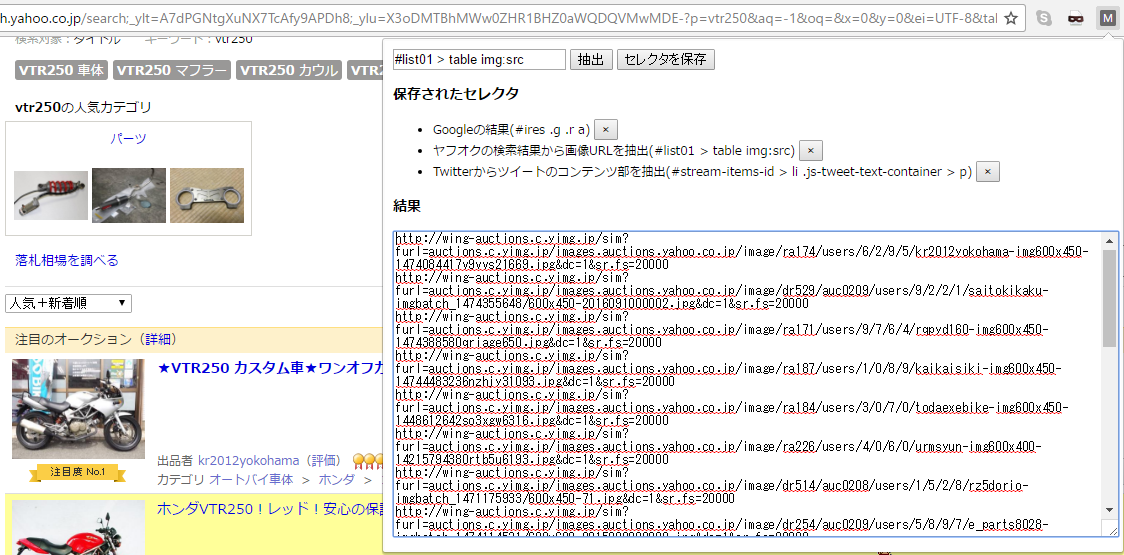
他にも、ヤフオクの検索結果一覧ページから、商品の画像を抽出したいのであれば、
[text] #list01 > table img:src[/text]
と入力すれば、商品画像のURL一覧が取得できます。
さり気なく登場させましたが、この拡張機能の仕様として、
[text] CSSセレクタの文字列:要素から取得した属性名[/text]
とコロン区切りで取得した属性名を受け付けるようにしています。
ですので、img要素のsrc属性(つまり表示画像のURL部分)を取得したいなら、xxx img:srcとかって入力すればokです。
そもそもCSSセレクタって何!?という方は…
Google先生にお願いします…
今回は以上です!